Co-Chair Hauraki Gulf Forum, Chair Auckland Conservation Board, Chair Aotea Conservation Advisory Park, Chair Te Pou Taiao
Title: Applying the principles of Te Tiriti o Waitangi in conservation management
In 2016, a Conservation Management Plan (CMP) for Hauturu o Toi was formally agreed upon by mana whenua Ngati Manuhiri and the Department of Conservation. I will discuss the principles that shaped the development of the CMP and the application of tikanga that is applied and the challenges to ensure that the mana and mauri of Hauturu o Toi is upheld.
Speaker: Dr Anna Santure, School of Biological Sciences, University of Auckland
Title: Sustaining our threatened hihi
Hihi (stitchbird) are a small, threatened forest bird that was once found across Te Ika-a-Māui (North Island). Although lost by the 1880s to all but a single offshore island, Te Hauturu-o-Toi (Little Barrier Island), reintroductions since the 1980s have successfully established seven new populations. I’ll discuss the successes and challenges of hihi conservation, and the role of detailed individual and population monitoring such as lifetime breeding and genetic diversity, in helping us learn how best to sustain hihi into the future.
Speaker: John Innes, Manaaki Whenua – Landcare Research
Title: The plight and conservation of mainland forest birds
New Zealand’s ancient forest birds are perfectly adapted to a world that no longer exists. Pest mammals and forest clearance have expunged some species to offshore islands, and some formerly widespread taxa are declining on our watch. What is being done to recover populations and could it be done better?
Conservation connectivity: from backyards and farms to landscapes
Date: Tuesday 16 June 2020 at 2pm
Speaker: Associate Professor Margaret Stanley – Te Kura Mātauranga Koiora/School of Biological Sciences, Te Whare Wānanga o Tāmaki Makaurau/University of Auckland, New Zealand
Description: Conservation in Aotearoa-New Zealand is heading toward landscape-scale conservation. By working at the landscape scale, we are aiming for ecological connectivity and functioning at a scale that makes sense for organisms and ecosystems. However, landscape scale conservation presents challenges across all scales: it encompasses a variety of habitat types and a variety of people.
In this webinar, Margaret will discuss both the positive and negative aspects of connectivity in farms and cities, and asks whether place-based conservation hinders landscape scale conservation.
Description: From carbon cycling to animal health, microbes mediate essential functions for life and the stability of systems worldwide. While scientists are racing to characterise microbial communities, a lack of understanding of microbial function has impeding progress.
Using examples from plant, soil and animal microbiomes, Manpreet will discuss how perturbation experiments that alter microbial communities and can reveal the function of these invisible powerhouses.
Better biosecurity by the numbers
Date: Tuesday 1 July 2020 at 2pm
Speaker:Professor Andrew Robinson – Director, CEBRA and Professor of Biosecurity, School/s of BioSciences and Mathematics & Statistics University of Melbourne, AustraliaRegister here
Description: Biosecurity focuses on protecting countries and regions against invasive pests, which are recognized by IUCN-World Conservation Union as the second most important cause of species extinction worldwide – and the main cause on islands.
CEBRA is the Centre of Excellence for Biosecurity Risk Analysis, jointly funded by the Australian and New Zealand governments to provide advice and develop tools for biosecurity risk analysis. Our research focuses on developing and implementing tools to assist in the management of biosecurity risk at national and international levels.
Andrew will describe in ringing terms a few showcase projects, underline some soaring successes, brush dismissively over our few dismal failures, and trawl selectively through the lessons learned.
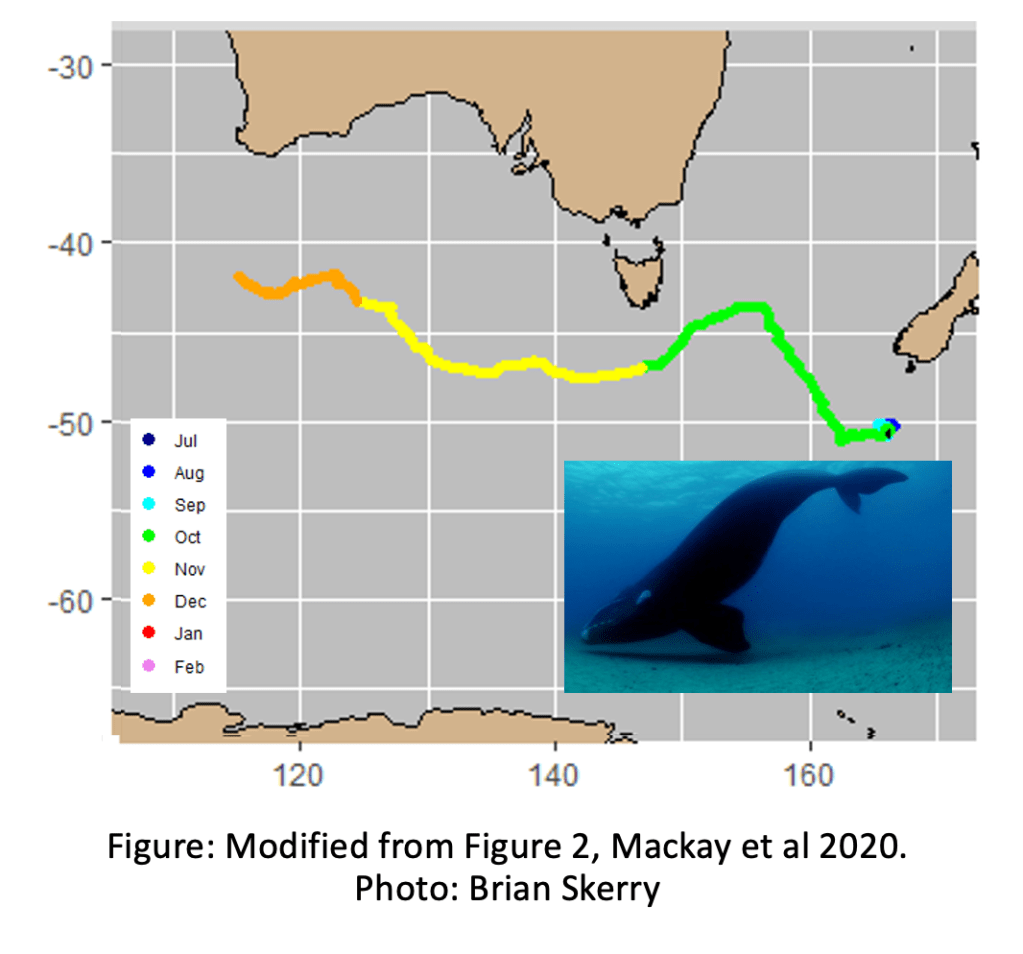
New work suggests that recovering whale populations can do unexpected things. Satellite tracked New Zealand southern right whales/ Tohorā nō Aotearoa (Tohorā) ended up west of New Zealand – 6000 km away from their historical summer feeding ground east of the Chatham Islands!
Tohorā are a remarkable conservation success story; from a low of perhaps 40 whales in 1920 around New Zealand, there were an estimated 2000 in 2009. Stopping the hunting and protecting their key wintering ground of the Auckland Islands / Maungahuka has given Tohorā a chance to recover. There are hopes they can regain their pre-whaling abundance of 30,000 whales. Changing ocean surface temperatures markedly impact their food sources. How much can we use historical records as a guide to where tohorā travel, particularly as the rate of environmental change accelerates? To help protect the whales further, it is important to understand changes in Tohorā migrations.
Credit: Ros Cole, Department of Conservation
A just-published pilot study, led by researchers from the South Australian Research and Development Institute, used satellite tags to understand where Tohorā go in the ~9 months of the year they are not in Maungahuka. Tohorā, like many marine species, show strong loyalty to migratory habitats; where they feed in summer and breed in winter. These migratory traditions, often learned from their mothers during their first year of life, help the whales find vital resources in a vast ocean.
The tagged Tohorā visited what is called the ‘subtropical converge’, south of Australia. This is where warm water from the tropics meets cool water from the Antarctic. By concentrating prey like plankton and fish, this convergence creates a reliable banquet for whales, and also penguins, albatross and seals. Right whales tracked from Australia also visited this area.
One went directly to the subtropical convergence, shown by this map:
The other Tohorā checked out the South Island before heading to the subtropical front:
This pilot study only tracked voyages of 2 of 2000 whales, but it raises the question: have Tohorā forgotten their traditional migratory routes to foraging grounds east of New Zealand?
A new collaboration between the University of Auckland, the Cawthron Institute (Nelson) and NOAA (National Oceanic and Atmospheric Administration, USA) will follow up on this work by combining ‘next-generation’ satellite tags to directly track the Tohorā’s journeys, with microchemical markers in the whale’s skin that can indicate where they feed, to understand today’s Tohorā voyages.
Hopefully, Tohorā can continue to learn from each other and their environment – they can find new and more productive foraging areas. Building these new traditions will make then resilient under climate change, but they need our help. Satellite telemetry will help us understand and protect their migratory routes and summer feeding grounds, supporting the population to recover further.
Emma Carroll is a Royal Society of New Zealand Rutherford Discovery Fellow in the School of Biological Sciences at the University of Auckland. This blog was also posted on Live Ocean: https://liveocean.com/blog/
“Not every decision needs to be green Mum” came the aggrieved voice of my teenage son about a decade ago. I do not remember what prompted the gripe, nor my response at the time (probably something lame, as fathoming the psyche of teenagers was not my best parenting skill). His lament has lingered with me, but here is how I would like to respond now: “Yes, they do – all our decisions need to be green. The world’s environmental challenges are too dire to start picking and choosing which times we make a green choice and which times we carry on regardless.” To be fair, this same son, 10 years later took time off work to be on the front line of the recent Extinction Rebellion climate change protests in Wellington!
So proud of my 82 year old Mum for joining my two sons on an Auckland climate march.
I was one of more than 11000 signatories on the 2019 World
Scientist’s Warning of Climate Emergency. Not only does this
highlight the perilous and imminent danger of climate change, but also it
outlines six immediate steps we need to take to make a major difference. From
reducing the use of fossil fuels and sequestering more CO2, to
stabilising human population growth, we need to act now. However, it is not
just climate change I’m concerned about; it is the accelerating loss of
biodiversity, the intensification of agricultural impacts, the overexploitation
of resources, rampant urban development, the pollution of our land and
waterways, and the continuous arrival and impact of pests and disease. Many of
these issues interact, requiring solutions that are multi-pronged and take a
holistic approach. For example, while planting and maintaining trees is
critical to reducing levels of CO2, if we focus on planting native rather
than exotic species then we also support our native biodiversity. And if we plant the native trees into a fenced
area that forms a buffer between cows and a waterway, then in one step we sequester
CO2, enhance native biodiversity and reduce nutrient runoff into our
waterways. Perfect!
Despite a lifetime committed to researching and communicating these issues, I have a sense of failure that it has been too little, too late. It is not enough just to keep warning folk of the catastrophic effect humans have on the planet; scientists also need to “Walk the Talk”. We need to demonstrate with personal action that we believe our own data and warnings. Physicist Shaun Hendy led the way in 2018 with a year of no flying, documented in his new book #NoFly.
So, beyond what I do professionally, here are what I
consider my top three personal actions to contribute to a more sustainable
future:
Reduced
intake of meat and meat products. Producing meat is environmentally costly.
Humans need to undertake a dietary shift to eat mostly plants and fewer animal
products. For me this is a work in progress as I am down to just one or two
meat meals a week. My “Not every decision needs to be green Mum” son is now way
ahead of me on this with his plant-based diet.
Kung Pow with hemp seeds & coriander;Trading favourite vegan recipes and sharing surplus home-grown fruit and vegetables has turned into a shared family passion
Reduce and mitigate carbon footprint. I favour walking where possible (the adolescent in me sometimes jumps onto a Lime scooter), but I mostly commute by bus. Air travel is trickier. Academics are frequent flyers as we connect with scientists around the globe, particularly when on research and study leave as I have been in 2019. To mitigate my extra travel this year, I calculated the air miles I have travelled (15,000 miles) and therefore the amount of carbon I generated (8000 pounds (3.63 tonnes)) so I could estimate how many trees I need to plant to offset my emissions (240 trees). A local landowner allowed us to fence off stock from a wetland, and to date this year I have planted 47 native trees into this restoration project. Only 200 trees to go!!
Another five trees planted into restoration area before breakfast (top). Delighted to see new growth on puriri planted about a month ago (lower).
More environmentally sustainable clothing choices. The pollution generated and resources squandered on clothing is mind boggling. It is complex to calculate the total environmental footprint of textiles, as it needs to include factors such as the pesticides and land used in farming cotton, pollution from manufacture (toxic dyes and other chemicals), waste from discarded clothing, and shipping. Op-shops are my friend as I have transitioned my wardrobe in the last decade or so to predominantly second-hand clothing. Most of my choices are low maintenance items that require no ironing (OK – that is more about laziness than saving electricity by not using an iron) and rejecting fast fashion by selecting items that will stand the test of time. The current standout is a top my mum made me when I was 17. Technically a “new” item in my wardrobe, but I have been wearing it for 40 years!
The environmental challenges we face are massive if we want the world to remain habitable for humans and retain biodiversity. For example, to keep global warming this century below 2°C, then we need to reduce our personal carbon footprint to 1.5 t per person by 2050. Around 70% of carbon emissions are actually made by just 100 companies, so is it worth the sacrifice to try to reduce your personal footprint when it is a minuscule drop in the bucket of what is needed? To me yes; everyone needs to engage in reducing their environmental impact, but we also need to demand systemic change away from GDP growth and the pursuit of affluence. Our goals should be to sustain ecosystems and improve human well-being. We need to act now.
Jacqueline Beggs is a Professor in Ecology at the School of Biological Sciences, University of Auckland. She is Director of the Centre for Biodiversity and Biosecurity and leads the Faculty of Science “A Sustainable Future” research theme.
I’m part of a National Science Challenge
project that has been looking at just that; considering how the
connectivity of bush patches on farms can help facilitate the movement of
native species across the landscape. Connectivity can be thought of in two
ways. Structural connectivity refers to how the vegetation is arranged, such as
spacing between habitat patches or corridors of vegetation between them, while
functional connectivity refers to species-specific needs and how species interact
with landscape structures, such as how far birds can fly between bush patches and
how large the patches need to be. So, if you are considering connectivity from
the perspective of a robin, then patches of vegetation may need to be as close as
100m from each other, compared to a kereru which can fly 10s of kilometres
between habitat patches.
It’s all well and good to enhance connectivity to help the robin, tūī or kōkako disperse and move throughout the landscape, but is this enhanced connectivity also facilitating the movement and populations of invasive mammalian predators? That would be a perverse outcome for bird species whose habitat we are aiming to improve. This is what I’m aiming to find out during my PhD. In particular I’ll be looking at feral cat movement on farms and how the distribution and arrangement of native vegetation influences their movement. Understanding cat movement on farms in relation to vegetation connectivity will help with both managing biodiversity and farmers hoping to minimise diseases, such as toxoplasmosis, on their farms.
Cathy is a PhD student in the Centre for Biodiversity & Biosecurity, School of Biological Sciences, University of Auckland. She is studing feral cat movement and landscape connectity in agroecosystems. She is supervised by Margaret Stanley, Hannah Buckley, Brad Case and Al Glen.
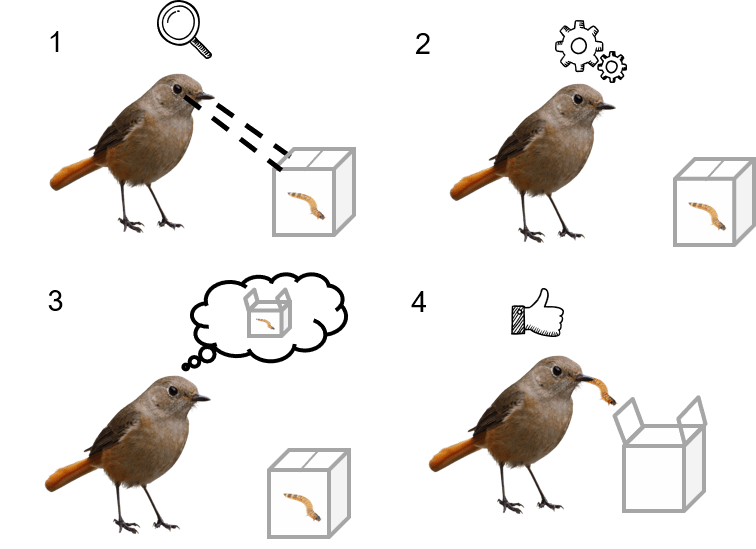
Animal cognition can be defined as the mechanisms in which
animals acquire, process, store and act on information of their environment
(Shettleworth, 1998).
Figure 1. Simplified representation of the cognitive mechanism (1.Acquire, 2.Proccess, 3.Store, 4.Act)
As a research area, animal cognition is relatively new and full of unanswered questions. Testing for cognitive ability in animals can be challenging. Many experiments are human-centric and based on what humans are good at, e.g. tool use, language, numerical counting… It is also complex to measure something we don’t fully understand. For instance, how can we test the cognitive ability of a mosquito when we can barely grasp how they perceive the world? But it is still in our nature to try to differentiate “us” (humans) from “them” (other animals).
The more we learn about what animals can do, the less humans seem unique. For example, tool use, which was thought to be an ability exclusive to humans, is also present in monkeys, birds, elephants, dolphins and even invertebrates such as octopuses and ants. Some animals are also able to manufacture their own tools by shaping leaves and sticks.
Figure 2. New Caledonian crow probing tree bark with a stick for insects. Image credit: James St Clair.
Further, there are some types of cognitive abilities that humans are very poor at and some animals excel. Spatial memory is one of them. Some species of birds and rodents , store food for times when resources are scarce and remember the exact location of their caches after weeks or months. Black-capped chickadees depend on stored food to survive during harsh winters and it is estimated that they can store up to 100 000 individual food items per year. Personally, I can’t relate to that. Every morning I forget where I put my keys and cell phone.
One of the biggest challenges in animal cognition research
is to design tests that are relevant to the animal being studied, while still being
comparable to other species. An animal that relies on smell to recognize peers,
would be unlikely to pass a mirror self-recognition test. Not because it is not
self-aware, but because the mirror does not provide the information needed for a
species that relies on olfactory (smell) cues instead of visual cues.
Figure 3. This cartoon illustrates one of the issues when testing for cognitive ability. Artist unknown.
Another example are bees, which are faster than most animals when it comes to associating a colour with a food reward. However, that does not mean bees are “smarter”, it reflects their well-developed (and necessary) ability to find colourful flowers to get food in their natural environment.
Therefore, whenever you get the urge to compare a chimpanzee with a 3-year-old child or to say that a dog is smarter than a fish, try to remember that there are different types of “intelligence” and they are all relative.
Juliane Gaviraghi Mussoi is a Ph.D. student from the University of Auckland. Her research focuses on vocalization, ornamentation and cognition of New Zealand fantails and Australian magpies. She is supervised by Dr. Kristal Cain and Dr. Margaret Stanley.
When I talk about plants and what may influence their growth and occurrence in an environment, it’s easy to mention the presence of sunlight or how much rainfall it gets. These factors we would class as abiotic – physical influences. When biotic factors are brought up, we would probably think of animals such as browsers, herbivores who graze on their favourite plants. But what is often not thought about are the interactions that microbial organisms have in a terrestrial forestry system.
I find that microbial concepts in ecology are so easily
looked over. This is probably due to a) we can’t observe their behaviour with
our naked eye and b) we often don’t know that they’re present in the
environment. With the development of advanced genetic technology in the last
20-30 years, we have a better idea of the microbial organisms present in the
environment and their potential role. In terrestrial systems, many of these
microbes interact with plants directly or indirectly. For the simplicity of this blog entry I will
be focusing on direct interactions. When a direct interaction occurs, this is
known as symbiosis.
Symbiosis is the term used to describe any biological interaction between two different organisms. The interaction may be positive, negative or neutral. The main types of symbiotic relationships are parasitism, commensalism and mutualism. Figure 1 sums up the different types of symbioses that are possible.
Figure 1: The types of symbiotic relationships that occur between two organisms (Species A and B). Interactions may be positive (beneficial to the species (+)), negative (undesirable to the species (-)) or neutral (no positive or negative influence (0))
When it comes to plants in a forest you would probably have come across one of the aforementioned interactions. A parasitic interaction between a microbial organism and a plant causes disease. Resources from a host allows the parasite to live and grow, increasing their fitness. However, the fitness of the host is decreased because this interaction is detrimental. Disease has caused mass population loss to forestry systems. You may have heard of the impact kauri dieback has had on the Waitakere Ranges in the New Zealand media. This effect has also been observed internationally, such as Rapid Ohia disease in Hawaii (Figure 2)
Figure 2: Rapid decline of Metrosideros polymorpha (Ohia) forest caused by the fungus Ceratocystis fimbriata. Puha District, Hawaii, USA
However, not all interactions with microbes are negative for plants. One of the most vital functions in a terrestrial ecosystem involves the mutualistic interaction between plants and mycorrhizal fungi. The fungal party are involved with enhanced nutrient cycling, stress tolerance and even communication between plant individuals in a forest system. Mutualistic interactions such as this allows improvement of fitness between the plant and the fungi. This is a very beneficial interaction, so much so that mycorrhizal fungi and terrestrial plants have co-evolved together multiple times over millions of years. Nowadays mycorrhizal fungi occur with approximately 90% of the world’s plants.
Figure 3: Light microscopic image of a root squash. This root squash shows a vesicle and hyphae from an arbuscular mycorrhizal fungi penetrating the root cortical cells of kauri (Agathis australis). This specimen was stained using Trypan Blue, highlighting fungal structures . 600x magnification
So the next time you go for a trip outdoors, have a look at the surrounding environment. Look at what plants are present and have a think about how they may be thriving. Are they in an ideal environment? Could something else be influencing their survival?
Find out more about microbial symbioses and genetic technology here: Roh, S., Abell, G., Kim, K., Nam, Y., & Bae, J. (2010). Comparing microarrays and next-generation sequencing technologies for microbial ecology research. Trends In Biotechnology, 28(6), 291-299.
Martin, F., Selosse, M., & Sanders, I. (2015). Mycorrhizal ecology and evolution: the past, the present, and the future. New Phytologist, 205(4), 1406-1423
van der Heijden, M., Bardgett, R., & van Straalen, N. (2008). The unseen majority: soil microbes as drivers of plant diversity and productivity in terrestrial ecosystems. Ecology Letters, 11(3), 296-310. van der Heijden, M.,
Megan Tan is a MSc student at the Joint School of Biodiversity and Biosecurity, University of Auckland. She is a recipient of the Sustainability Research Award for Students 2019 and has also received funding from the Centre for Biodiversity and Biosecurity. Her research is focusing on the effects of mycorrhizal fungi symbiosis on kauri growth. This study is supervised by Bruce Burns of the University of Auckland and Maj Padamsee of Manaaki Whenua Landcare Research. Megan is also a big fan of sweets
This month I visited Australia for
the first time in my life and was very impressed by the number of wildlife
encounters I experienced in only 10 days! As an ornithologist, I always pay
attention to birds and what they are up to. The avian diversity as well as all
the noises the creatures were producing was simply overwhelming. But there was
one thing which added significantly to the Aussie bird chorus and disturbed not
just me, but other birds as well. I am talking about mobbing, which I have
observed many times both in Europe and now in Australia, but never in New
Zealand.
Fig. 1 Mobbing a hawk.
Mobbing is a popular term and
is used to describe bullying of an individual by a person or a group in any
context. However, not many people know that this sociological term was first
described by the remarkable and outstanding ‘father of ethology’, Konrad Lorenz in 1966. Lorenz
observed this behaviour among birds and other animals and suggested it has
something to do with the deepest animal instincts aimed at surviving and
protecting a group. Later it was found that some non-predator birds use mobbing
against diurnal and night predators, such as owls, hawks, etc. Mobbing birds
fly in very noisy and angry groups around a roosting place or a tree hole where
they found a predator to attract as much attention as possible and to finally
make their enemy retreat from the area. It makes perfect sense for them to get rid
of potential threats before darkness falls when they all become helpless while
roosting. It also explains why night hunters have camouflage plumage and sit
still in the day with their eyes closed. Nothing could be more frustrating than
to be awakened by a bunch of clamorous moppets!
Fig. 2 Crows mobbing long-eared owl.
The way evolution works, one
advantage can often be used in a different context. As I’ve mentioned, bird
diversity in Australia is exceptionally high, which leads to high competition for
resources. The scene I witnessed in Sydney, was a mobbing of a kookaburra
family by species with a very self-explanatory name, the noisy miner. I was sad
to see it, not only because the population of kookaburras is declining while
the population of noisy miners grows exponentially, but also because I am very fond
of kookaburras. These birds feed mostly on small animals and rarely on smaller
birds, imposing no threat to things like noisy miners. However, when we think
of evolutionary pathways, we could conclude, that mobbing in this situation is
directed to resource and space access, which is indirectly connected to
survival, rather than direct mortality.
Fig.3 A pair of kookaburras recovering from the stress of being mobbed by noisy miners.
In New Zealand mobbing is not that widespread probably due to the low number of natural avian or mammalian predators. Brent Stephenson showed that morepork is mobbed by at least 9 passerine species, including natives like fantail, silvereye, saddleback, stitchbird and tui. Alison Stanes revealed that the native diurnal predator, the swamp harrier, gets mobbed by colonial birds, such as stilts. But how about mobbing invasive pests? A very interesting work by Richard Maloney and Ian McLean showed that native New Zealand robins were capable of recognising and mobbing stoats after a one-event learning experience. The good news for us is that this study suggests predator training may be a valuable addition to many reintroduction programmes for endangered species. Let’s mob the pest away!
Daria Erastova is a PhD student at
the School of Biological Sciences, University of Auckland, who studies the effect
of sugar-water feeding on behaviour and health of native New Zealand birds in
urban context. This research is supervised by Margaret Stanley, Kristal Cain
(The University of Auckland) and Josie Galbraith (War Memorial Museum). The
study is funded by Birds New Zealand, Forest and Bird, and Centre for
Biodiversity and Biosecurity.
Recently, I had the opportunity to hear Dame Dr. Jane Goodall speak about her Roots & Shoots program at Kristin School. Her intense passion for science began when, as a little girl, she saved money and bought as many second-hand books as she could. One book, ‘Tarzan of the Apes’, which she still treasures, caught her attention. She fell in love with Tarzan, but what did Tarzan do? He fell in love with the wrong Jane. Heartbreak aside, Tarzan inspired her to grow up, live in Africa among wild animals, and write books about them. Seventy-five years later, Jane has realized her dreams and more. For 50 years, she has revolutionized the field of primatology and redefined species conservation to include the needs of local societies and environments.
Dr. Goodall, clutching her ever-popular handful of soft toys, began her talk by declaring that every person can make a difference, especially the youth. Announcing that young people are some of the most compassionate and creative solutionaries our world has seen. She founded Roots & Shoots, in 1991, to empower and encourage young people to pursue their passion, rally their peers and become the compassionate leaders our world needs to ensure a better future for animals, people, and environment (A.P.E.). Roots & Shoots started with 12 students in Tanzania and has grown to 150,000 groups helping develop skills for young people worldwide. The organizations’ mission is to promote respect and compassion for all organisms, further understanding of all cultures and beliefs, and to inspire everyone to act to make the world a better place.
Various Roots & Shoots projects are currently undertaken by Kiwi students, from kindergarteners planting gardens to attract bees and butterflies; to educating local communities near Mount Pirongia about endangered bats; and even the famous the ‘BAN THE BAG’ campaign. Students from the De La Salle College gave a presentation about implementing their ‘Our Stream, Our Taonga’ restoration project on a small stream that runs through their campus and flows into Otaki Creek. The land around the stream was open fields, saturated with weeds. Rain runoffs from the area, leaf litter and rubbish used to flow into the stream resulting in an unpleasant smell and an unhealthy waterway. The students understood that people had destroyed this ecosystem and they had to do something or else it would never change. A small group of students in 2015 took charge of the clean-up and started small. They pulled out debris from the stream, including tires, branches, and even a bicycle. Next, they cleared weeds from the creek banks and planted native trees to stop soil runoff, increasing oxygen levels, restoring carbon into the ecosystem and attracting birds and insects. Since 2015, 100 students and staff have maintained this project and planted approximately 3,500 native trees. The students continue to monitor, pH, and water clarity along with birds, fish, and invertebrate, who have all returned in numbers to the stream.
Dr. Goodall stated there
has been a disconnect between our brains and the human heart and “only when
head and heart work in harmony can we attain our true human potential.” The
Roots & Shoots program is hugely beneficial and an excellent way of
involving students to think about imparting positive impacts in their world, and
encouraging them to work within their local communities to achieve a global
goal.
You can follow the Jane Goodall Institute New Zealand @jane_goodall_nz on Instagram and @JGI_NZ on Twitter
Kaavya is a MSc student studying the spread of exotic insects into natural ecosystems in New Zealand, and is supervised by Darren Ward at the University of Auckland and Landcare Research.
New Zealand is a weird place for biodiversity. An
estimated 20,000 invertebrate species live in New Zealand and at least 50% are
undescribed. When discussed, perhaps most often mentioned is the ‘high degree
of endemism’. This is the proportion of species found only in NZ and nowhere
else in the world. Overall, about 90% of insect species in NZ are endemic.
What is far less appreciated is the number of new
species still to be discovered and described. I am often asked ‘Are there still
new species to be found in NZ?’ Yes, there are, and many hundreds of them.
Recently, twenty-four new species of Mecodema, a genus of large-bodied ground beetles, have been described (Seldon & Buckley 2019), with one species even from Clevedon in the northern Wairoa! This genus is highly diverse with species spread throughout mainland New Zealand, and on many offshore islands. Many species are found in relatively restricted geographic areas and their presence indicates past geological events which have shaped New Zealand; including, isolation from the mainland, diversification and adaption in alpine zones; and volcanic activity.
Just this week, a new species of parasitoid wasp, Sierola houdiniae, was described (see Magnacca 2019) from a single specimen, reared from the larvae of a caterpillar, Houdinia flexilissima, better known as “Fred the Thread”. The caterpillar is found in Waikato bogs and peatlands in the living stems of Sporadanthus ferrugineus, a large endemic New Zealand rush, and is considered a species of high conservation status.
Discovering such hidden diversity is an important part
of understanding how the world works, but also gives a sense of wonder about the
diversity of the weird and wonderful little critters around us.
Darren Ward
is an entomologist in the New Zealand Arthropod Collection at Landcare
Research, and a senior lecturer at the School of Biological Sciences,
University of Auckland.
Seldon & Buckley. 2019. The genus Mecodema Blanchard 1853 (Coleoptera:
Carabidae: Broscini) from the North Island, New Zealand. Zootaxa. doi.org/10.11646/zootaxa.4598.1.1
Magnacca. 2019. Two new species of Sierola Cameron (Hymenoptera:
Bethylidae) from New Zealand and Australia. New Zealand Entomologist. doi.org/10.1080/00779962.2019.1602899
 Speaker: Nicola MacDonald, Ngati Rehua, Ngati Wai
Speaker: Nicola MacDonald, Ngati Rehua, Ngati Wai Speaker: Dr Anna Santure, School of Biological Sciences, University of Auckland
Speaker: Dr Anna Santure, School of Biological Sciences, University of Auckland Speaker: John Innes, Manaaki Whenua – Landcare Research
Speaker: John Innes, Manaaki Whenua – Landcare Research